Overview
Glossary
- Data Providers: Provide On-Chain or Off-Chain data
- Data Consumers: Consumers like LLM / Developers / Data Engineer and so on.
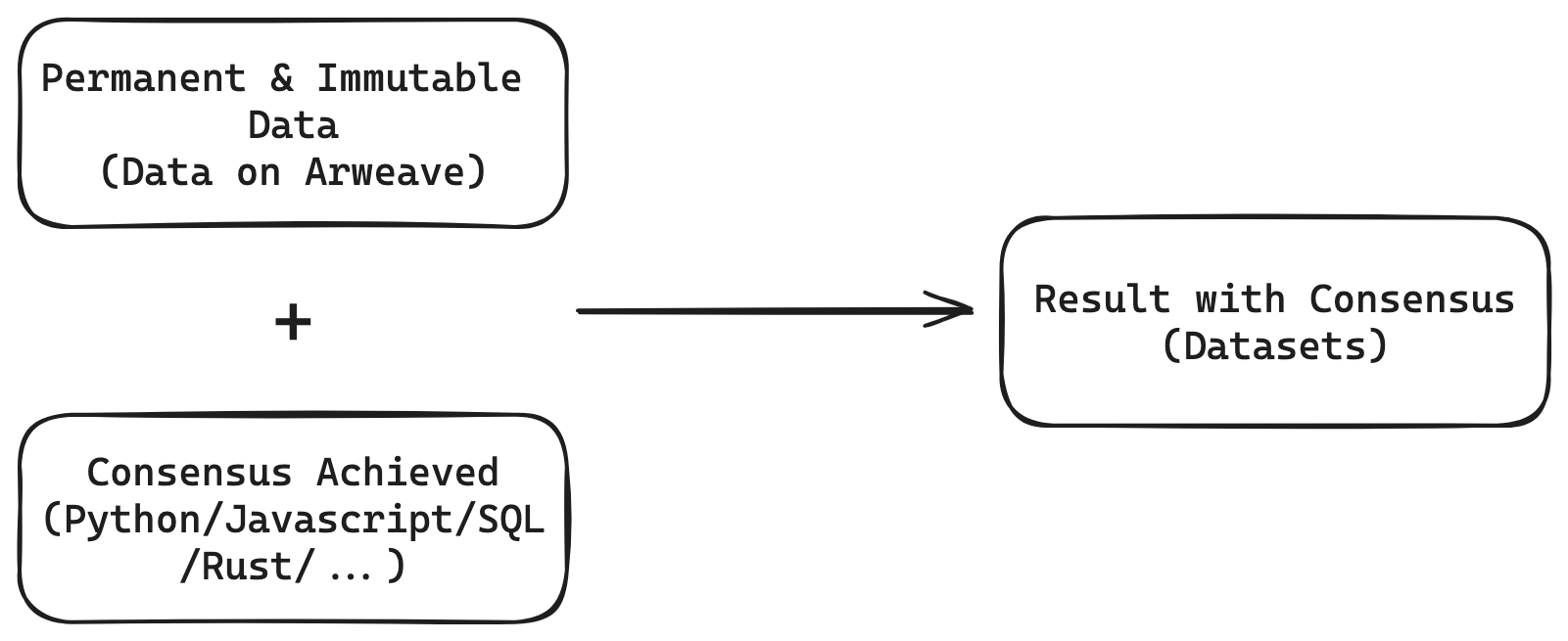
- SCP: Storage-Based Consensus Paradigm. This is how the dataset is being proved.
- CDC(Changelog): Change Data Capture. Data stored permanently in Arweave, like changelog which generated by CDC.
- Dataset: Data set which is stored in any database or file system. It can be accessed directly by the data consumer through API / SQL / Sync.
- Data Manifest: Data manifest is a metadata file that contains the information about the dataset.
Data Flow
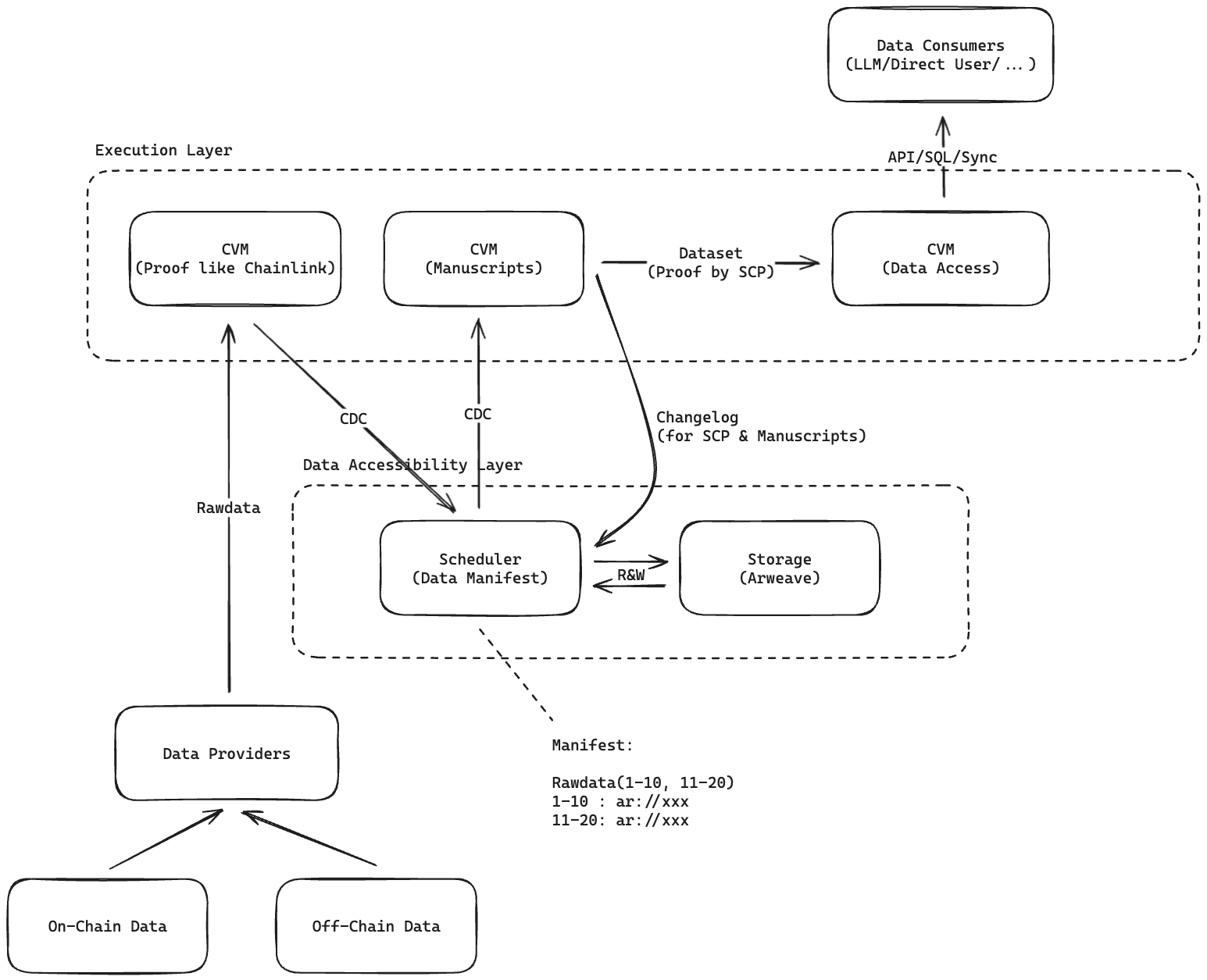
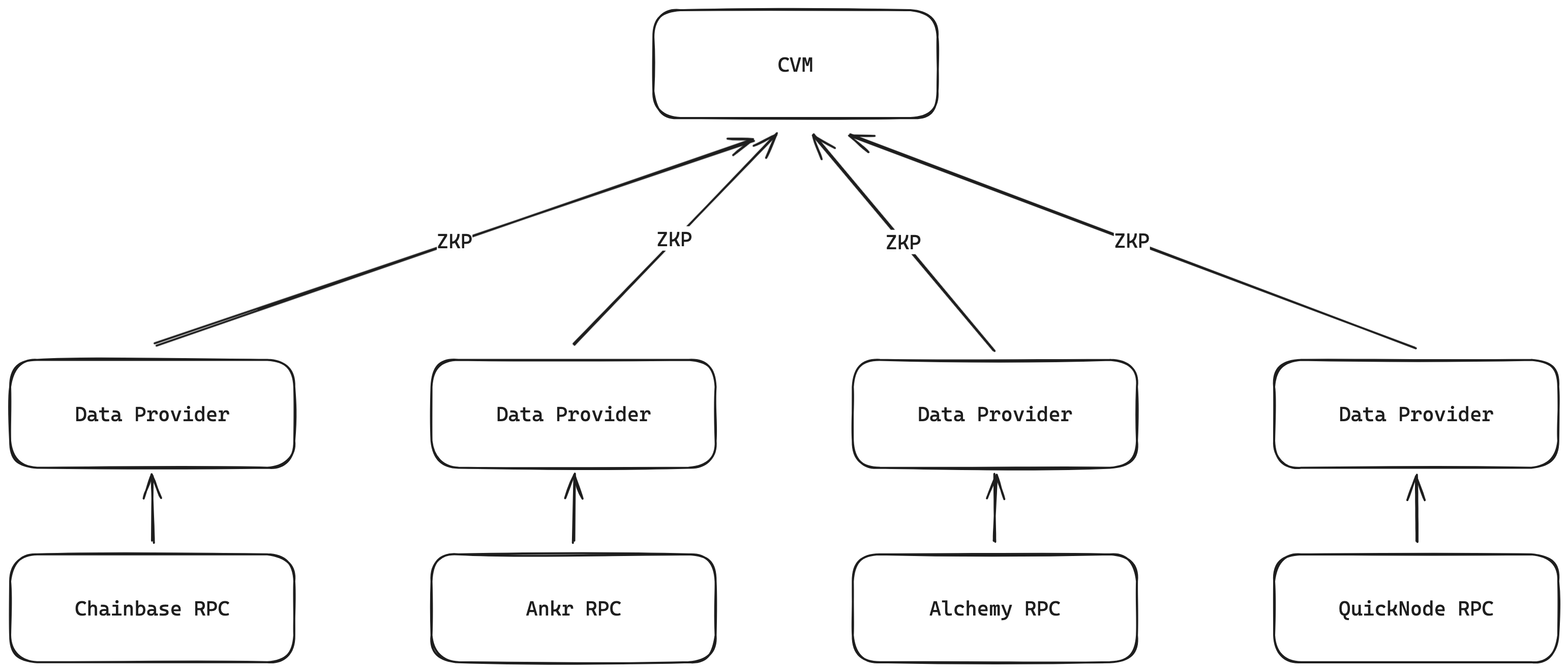
- Data Providers collect On-Chain & Off-Chain data, then push the data with Zero-Knownledge Proof to CVM.
- The CVM verifies the raw data provided by the Data Provider and writes the data permanently and immutably into Arweave in the form of a Changelog(CDC), while updating the data index in the Manifest.
- The Manuscript consumes the raw data in a streaming manner using the CDC approach to extract and process high-value data.
- The processed data can be directly stored in a database or local files, and the CVM provides direct data access services via SQL/API/Sync
Solved Problems
Distributed Data Lake
The raw data is stored immutably and in a decentralized manner on Arweave. The data is shared according to specific rules and uploaded to Arweave after sharding. The data shards are maintained through a Manifest and the query index is provided by the Scheduler. The structure of the Manifest is as follows: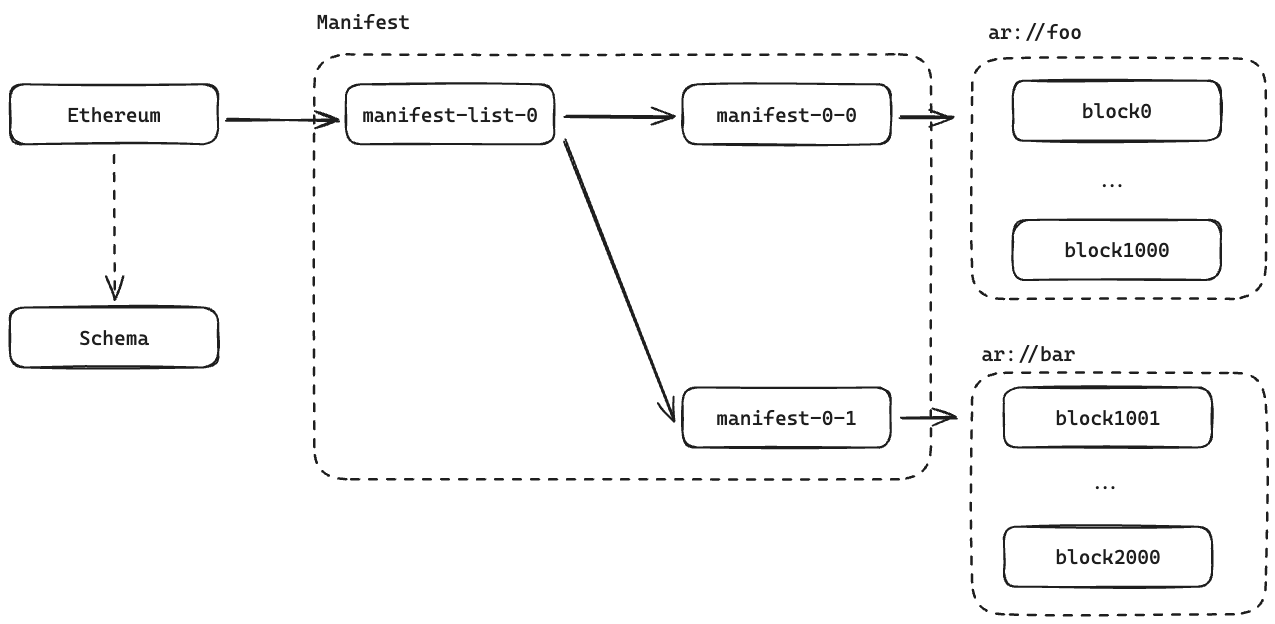
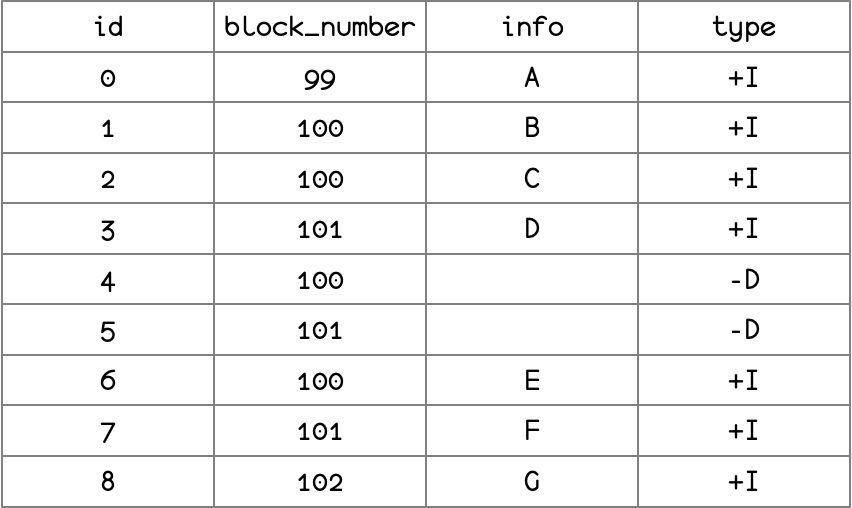
- Elegantly solves the Reorg issue in blockchain data.
- Data is written in an Append Only manner, eliminating the need to handle conflicts, allowing for optimal data freshness.
- The downstream CVM can continuously read upstream data in a streaming manner then process it. While benefiting from the compounding effect of upstream data, the downstream data also maintains good data freshness.
Proof of Raw Data
Proof of Indexed Data
Indexed Data is verified using SCP(Storaged-Based Consensus Paradigm). The basic principles are as follows: